Datalog in Javascript
Stepan12 min read
Query engines make me feel like a wizard. I cast my incantation: “Give me all the directors and the movies where Arnold Schwarzenegger was a cast member”. Then charges zip through wires, algorithms churn on CPUs, and voila, an answer bubbles up.
How do they work? In this essay, we will build a query engine from scratch and find out. In 100 lines of Javascript, we’ll supports joins, indexes, and find our answer for Arnold! Let’s get into it.
Choice
Our first step is to choose which language we’ll support. SQL is the most popular, but we wouldn’t get far in 100 lines. I suggest we amble off the beaten path and make Datalog instead.
If you haven’t heard of Datalog, you’re in for a treat. It’s a logic-based query language that’s as powerful as SQL. We won’t cover it completely, but we’ll cover enough to fit a good weekend’s worth of hacking.
To grok Datalog, we need to understand three ideas:
Data
The first idea is about how we store data.
SQL Tables
SQL databases store data in different tables:

Here we have a
movie table, which stores one movie per row. The record with the id 200 is "The Terminator".Notice the
director_id. This points to a row in yet another person table, which keeps the director’s name, and so on.Datalog Triples
In Datalog databases, there are no tables. Or really everything is just stored in one table, the
triple table:
A
triple is a row with an id, attribute, and value. Triples have a curious property; with just these three columns, they can describe any kind of information!How? Imagine describing a movie to someone:
It's called "The Terminator" It was released in 1987
Those sentences conveniently translate to triples:
[200, movie / title, 'The Terminator'][(200, movie / year, 1987)];
And those sentences have a general structure; if you can describe a movie this way, you can describe tomatoes or airplanes just as well.
Queries
The second idea is about how we search for information.
SQL Algebra
SQL has roots in relational algebra. You give the query engine a combination of clauses and statements, and it gets you back your data:
SELECT id FROM movie WHERE year = 1987
This returns:
[{ id: 202 }, { id: 203 }, { id: 204 }];
Voila, the movie ids for Predator, Lethal Weapon, and RoboCop.
Datalog Pattern Matching
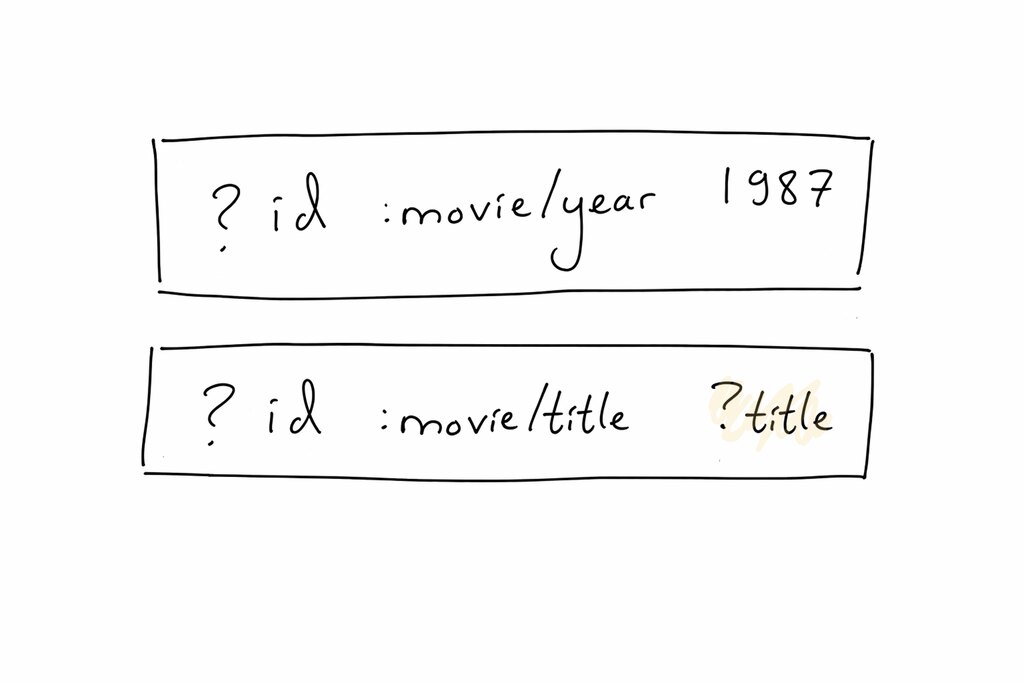
Datalog databases rely on pattern matching. We create “patterns” that match against triples. For example, to find all the movies released in 1987, we could use this pattern:
[?id, movie/year, 1987]
Here,
?id is a variable: we’re telling the query engine that it can be any value. But, the attribute must be movie/year, and the value must be 1987.
Our query engine runs through triple after triple. Since
?id can be anything, this matches every triple. But, the attribute movie/year and the value 1987 filter us down to just the triples we care about:[
[202, movie / year, 1987],
[203, movie / year, 1987],
[204, movie / year, 1987],
];
Notice the
?id portion; those are the ids for Predator, Lethal Weapon, and RoboCop!Datalog find
In SQL, we just got back ids though, while our query engine returned more. How can we support returning ids only? Let’s adjust our syntax; here’s
find:{ find: [?id],
where: [
[?id, movie/year, 1987]
] }
Our query engine can now use the
find section to return what we care about. If we implement this right, we should get back:[[202], [203], [204]];
And now we’re as dandy as SQL.
Joins
The third idea is about how joins work. Datalog and SQL’s magic comes from them.
SQL clauses
In SQL, if we wanted to find “The Terminator’s” director, we could write:
SELECT
person.name
FROM movie
JOIN person ON movie.director_id = person.id
WHERE movie.title = "The Terminator"
Which gets us:
[{ name: 'James Cameron' }];
Pretty cool. We used the
JOIN clause to connect the movie table with the person table, and bam, we got our director’s name.Datalog…Pattern Matching
In Datalog, we still rely on pattern matching. The trick is to match multiple patterns:
{
find: [?directorName],
where: [
[?movieId, movie/title, "The Terminator"],
[?movieId, movie/director, ?directorId],
[?directorId, person/name, ?directorName],
],
}
Here we tell the query engine to match three patterns. The first pattern produces a list of successful triples. For each successful triple, we search again with the second pattern, and so on. Notice how the
?movieId and ?directorId are repeated; this tells our query engine that for a successful match, those values would need to be the same across our different searches.What do I mean? Let’s make this concrete; here’s how our query engine could find The Terminator’s director:

The first pattern finds:
[200, movie/title, "The Terminator"].
We bind
?movieId to 200. Now we start searching for the second pattern:[?movieId, movie/director, ?directorName].
Since
?movieId needs to be 200, this finds us[200, movie / director, 100];
And we can now bind
?directorId to 100. Time for the third pattern:[?directorId, person/name, ?directorName]
Because
?directorId has to be 100, our engine finds us:[100, person / name, 'James Cameron'];
And perfecto, the
?directorName is now bound to "James Cameron"! The find section would then return ["James Cameron"].Oky doke, now we grok the basics of Datalog! Let’s get to the code.
Syntax
First things first, we need a way to represent this syntax. If you look at:
{ find: [?id],
where: [
[?id, movie/year, 1987]
] }
We could almost write this in Javascript. We use objects and arrays, but
?id and movie/year get in the way; they would throw an error. We can fix this with a hack: let’s turn them into strings.{ find: ["?id"],
where: [
["?id", "movie/year", 1987]
] }
It’s less pretty, but we can now express our queries without fanfare. If a string begins with a question mark, it’s a variable. An attribute is just a string; it’s a good idea to include a namespace like
"movie/*", but we won’t force our users.Sample Data
The next thing we’ll need is sample data to play with. There’s a great datalog tutorial [1], which has the movie dataset we’ve been describing. I’ve taken it and adapted it to Javascript. Here’s the file.
// exampleTriples.js
export default [
[100, 'person/name', 'James Cameron'],
[100, 'person/born', '1954-08-16T00:00:00Z'],
// ...
];
Let’s plop this in and require it:
import exampleTriples from './exampleTriples';
Now for our query engine!
matchPattern
Goal
Our first goal is to match one pattern with one triple. Here’s an example:

We have some variable bindings:
{"?movieId": 200}. Let’s call this a context.Our goal is to take a pattern, a triple, and a context. We’ll either return a new context:
{"?movieId": 200, "?directorId": 100}
Or a failure. We can just say
null means failure.This could be the test we play with:
expect(
matchPattern(
['?movieId', 'movie/director', '?directorId'],
[200, 'movie/director', 100],
{ '?movieId': 200 },
),
).toEqual({ '?movieId': 200, '?directorId': 100 });
expect(
matchPattern(
['?movieId', 'movie/director', '?directorId'],
[200, 'movie/director', 100],
{ '?movieId': 202 },
),
).toEqual(null);
Code
Nice, we have a plan. Let’s write the larger function first:
function matchPattern(pattern, triple, context) {
return pattern.reduce((context, patternPart, idx) => {
const triplePart = triple[idx];
return matchPart(patternPart, triplePart, context);
}, context);
}
We take our pattern, and compare each part to the corresponding one in our triple:

So, we’d compare
"?movieId" with 200, and so on.matchPart
We can delegate this comparison to
matchPart:function matchPart(patternPart, triplePart, context) {
if (!context) return null;
if (isVariable(patternPart)) {
return matchVariable(patternPart, triplePart, context);
}
return patternPart === triplePart ? context : null;
}
First we address
context; if context was null we must have failed before, so we just return early.isVariable
Next, we check if we’re looking at a variable.
isVariable is simple enough:function isVariable(x) {
return typeof x === 'string' && x.startsWith('?');
}
matchVariable
Now, if we are looking at a variable, we’d want to handle it especially:
function matchVariable(variable, triplePart, context) {
if (context.hasOwnProperty(variable)) {
const bound = context[variable];
return matchPart(bound, triplePart, context);
}
return { ...context, [variable]: triplePart };
}
We would check if we already have a binding for this variable. For example, when comparing
?movieId, we’d already have the binding: “200”. In this case, we just compare the bound value with what’s in our triple.// ...
if (context.hasOwnProperty(variable)) {
const bound = context[variable];
return matchPart(bound, triplePart, context);
}
// ...
When we compare
?directorId though, we’d see that this variable wasn’t bound. In this case, we’d want to expand our context. We’d attach ?directorId to the corresponding part in our triple (100).return { ...context, [variable]: triplePart };
Finally, if we weren’t looking at a variable, we would have skipped this and just checked for equality. If the pattern part and the triple part match, we keep the context; otherwise we return null:
// ...
return patternPart === triplePart ? context : null;
// ...
And with that,
matchPattern works as we like!querySingle
Goal
Now for our second goal. We can already match one pattern with one triple. Let’s now match one pattern with multiple triples. Here’s the idea:

We’ll have one pattern and a database of triples. We’ll want to return the contexts for all the successful matches. Here’s the test we can play with:
expect(
querySingle(['?movieId', 'movie/year', 1987], exampleTriples, {}),
).toEqual([{ '?movieId': 202 }, { '?movieId': 203 }, { '?movieId': 204 }]);
Code
Well, much of the work comes down to
matchPattern. Here’s all querySingle needs to do:function querySingle(pattern, db, context) {
return db
.map((triple) => matchPattern(pattern, triple, context))
.filter((x) => x);
}
We go over each triple and run
matchPattern. This would return either a context (it’s a match!), or null (it’s a failure). We filter to remove the failures, and querySingle works like a charm!queryWhere
Goal
Closer and closer. Now to support joins. We need to handle multiple patterns:

So we go pattern by pattern, and find successful triples. For each successful triple, we apply the next pattern. At the end, we’ll have produced progressively larger contexts.
Here’s the test we can play with:
expect(
queryWhere(
[
['?movieId', 'movie/title', 'The Terminator'],
['?movieId', 'movie/director', '?directorId'],
['?directorId', 'person/name', '?directorName'],
],
exampleTriples,
{},
),
).toEqual([
{ '?movieId': 200, '?directorId': 100, '?directorName': 'James Cameron' },
]);
Code
This too, is not so difficult. Here’s queryWhere:
function queryWhere(patterns, db) {
return patterns.reduce(
(contexts, pattern) => {
return contexts.flatMap((context) => querySingle(pattern, db, context));
},
[{}],
);
}
We start off with one empty context. We then go pattern by pattern; for each pattern, we find all the successful contexts. We then take those contexts, and use them for the next pattern. By the end, we’ll have all the expanded contexts, and
queryWhere works like a charm too!Query
Goal
And now we’ve just about built ourselves the whole query engine! Next let’s handle
where and find.This could be the test we can play with:
expect(
query(
{
find: ['?directorName'],
where: [
['?movieId', 'movie/title', 'The Terminator'],
['?movieId', 'movie/director', '?directorId'],
['?directorId', 'person/name', '?directorName'],
],
},
exampleTriples,
),
).toEqual([['James Cameron']]);
Code
Here’s
query:function query({ find, where }, db) {
const contexts = queryWhere(where, db);
return contexts.map((context) => actualize(context, find));
}
Our
queryWhere returns all the successful contexts. We can then map those, and actualize our find:function actualize(context, find) {
return find.map((findPart) => {
return isVariable(findPart) ? context[findPart] : findPart;
});
}
All
actualize does is handle variables; if we see a variable in find, we just replace it with its bound value. [2]Play
And voila! We have a query engine. Let’s see what we can do.
When was Alien released?
query(
{
find: ['?year'],
where: [
['?id', 'movie/title', 'Alien'],
['?id', 'movie/year', '?year'],
],
},
exampleTriples,
);
[[1979]];
What do I know about the entity with the id
200 ?query(
{
find: ['?attr', '?value'],
where: [[200, '?attr', '?value']],
},
exampleTriples,
);
[
['movie/title', 'The Terminator'],
['movie/year', 1984],
['movie/director', 100],
['movie/cast', 101],
['movie/cast', 102],
['movie/cast', 103],
['movie/sequel', 207],
];
And, last by not least…
Which directors shot Arnold for which movies?
query(
{
find: ['?directorName', '?movieTitle'],
where: [
['?arnoldId', 'person/name', 'Arnold Schwarzenegger'],
['?movieId', 'movie/cast', '?arnoldId'],
['?movieId', 'movie/title', '?movieTitle'],
['?movieId', 'movie/director', '?directorId'],
['?directorId', 'person/name', '?directorName'],
],
},
exampleTriples,
);
🤯
[
['James Cameron', 'The Terminator'],
['John McTiernan', 'Predator'],
['Mark L. Lester', 'Commando'],
['James Cameron', 'Terminator 2: Judgment Day'],
['Jonathan Mostow', 'Terminator 3: Rise of the Machines'],
];
Now this is cool!
Indexes
Problem
Okay, but you may have already been thinking, “Our query engine will get slow”.
Let’s remember
querySingle:function querySingle(pattern, db, context) {
return db
.map((triple) => matchPattern(pattern, triple, context))
.filter((x) => x);
}
This is fine and dandy, but consider this query:
querySingle([200, "movie/title", ?movieTitle], db, {})
We want to find the movie title for the entity with the id
200. SQL would have used an index to quickly nab this for us.But what about our query engine? It’ll have to search every single triple in our database!
Goal
Let’s solve that. We shouldn’t need to search every triple for a query like this; it’s time for indexes.
Here’s what we can do; Let’s create
entity, attribute, and value indexes. Something like:{
entityIndex: {
200: [
[200, "movie/title", "The Terminator"], [200, "movie/year", 1984],
//...
],
// ...
},
attrIndex: {
"movie/title": [
[200, "movie/title", "The Terminator"],
[202, "movie/title", "Predator"],
// ...
],
// ...
},
}
Now, if we had a pattern like this:
[200, "movie/title", ?movieTitle]
We could be smart about how to get all the relevant triples: since
200 isn’t a variable, we could just use the entityIndex. We’d grab entityIndex[200] , and voila we’d have reduced our search to just 7 triples!We can do more, but with this we’d already have a big win.
createDB
Okay, let’s turn this into reality. We can start with a proper
db object. We were just using exampleTriples before; now we’ll want to keep track of indexes too. Here’s what we can do:function createDB(triples) {
return {
triples,
entityIndex: indexBy(triples, 0),
attrIndex: indexBy(triples, 1),
valueIndex: indexBy(triples, 2),
};
}
We’ll take our triples, and start to index them.
indexBy
And
indexBy will handle that. It can just take the triples and create a mapping:function indexBy(triples, idx) {
return triples.reduce((index, triple) => {
const k = triple[idx];
index[k] = index[k] || [];
index[k].push(triple);
return index;
}, {});
}
Here
idx represents the position in the triple; 0 would be entity, 1 would be attribute, 2 would be value.querySingle, updated
Now that we have indexes, we can use them in querySingle:
export function querySingle(pattern, db, context) {
return relevantTriples(pattern, db)
.map((triple) => matchPattern(pattern, triple, context))
.filter((x) => x);
}
The only change is
relevantTriples. We’ll lean on it to figure out which index to use.relevantTriples
Here’s all relevantTriples does:
function relevantTriples(pattern, db) {
const [id, attribute, value] = pattern;
if (!isVariable(id)) {
return db.entityIndex[id];
}
if (!isVariable(attribute)) {
return db.attrIndex[attribute];
}
if (!isVariable(value)) {
return db.valueIndex[value];
}
return db.triples;
}
We take the pattern. We check the id, attribute, and the value. If any of them aren’t variables, we can safely use the corresponding index.
With that, we’ve made our query engine faster 🙂
Fin
I hope you had a blast making this and got a sense of how query engines work to boot. If you’d like to see the source in one place, here it is.
More
This is just the beginning. How about functions like “greater than” or “smaller than”? How about an “or” query? Let’s not forget aggregate functions. If you’re curious about this, I’d suggest three things:
First go through the Learn Datalog website; that’ll give you a full overview Datalog. Next, I’d suggest you go through the SICP chapter on logic programming. They go much further than this essay. Finally, you can look at Nikita Tonsky’s datascript internals, for what a true production version could look like.
Credits
Huge credit goes to SICP. When I completed their logic chapter, I realized that query languages didn't have to be so daunting. This essay is just a simplification of their chapter, translated into Javascript. The second credit needs to go to Nikita Tonsky’s essays. His Datomic and Datascript internals essays are a goldmine. Finally, I really enjoyed Learn Datalog, and used their dataset for this essay.
Thanks to Joe Averbukh, Irakli Safareli, Daniel Woelfel, Mark Shlick, Alex Reichert, Ian Sinnott, for reviewing drafts of this essay.
Footnotes
-
Learn Datalog Today — very fun! ↩
-
You may be wondering, won’t
findalways have variables? Well, not always. You could include some constant, like{find: ["movie/title", "?title"]}↩